Overview of Hadoop Stack
Tez - execution engine , runs on top of YARN
Applications and Framework
- HBASE: BigTable
- Hive: data summarization and querying
- Pig data flow language
- Spark - computation engine
HDFS and HDFS2
HDFS
Goal:
Requiremnt
- Resiliance, can handle fialreu
- Scalable, namespace issue,
- Application Locality
- Portability
Design:
- one namenode
- Multiple datanode
HDFS2:
- HDFS Federation
- multiple namespaces
- block pools
Design:
- multiple namenode servers
- Multiple namespaces
- Block pools
- high availability
- heterogenious storage: SSD, RAM, etc
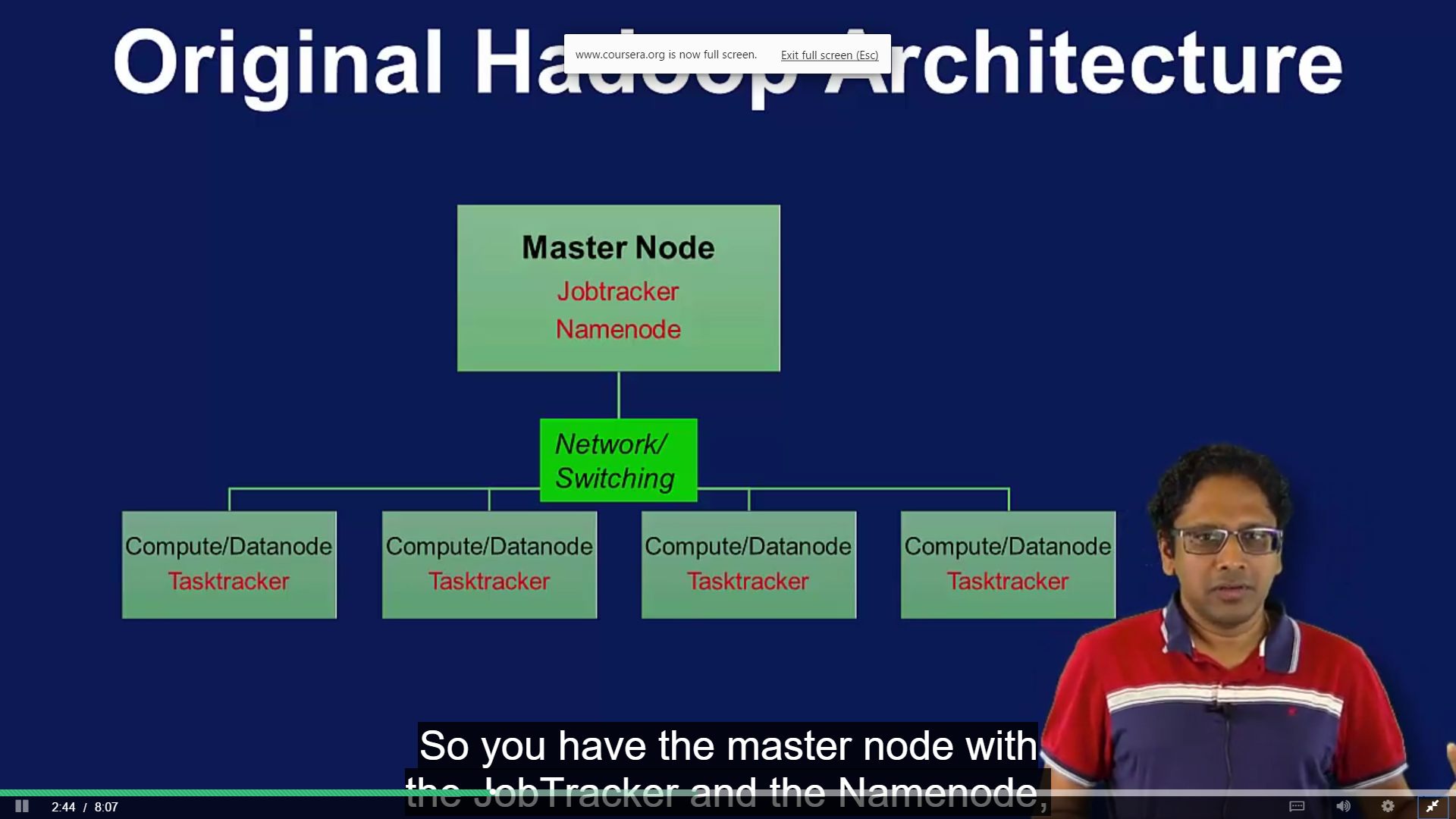
YARN
- Jobtracker
- Tasktracker gets the request form jobtracker and process them
- executes task per jobtracker request
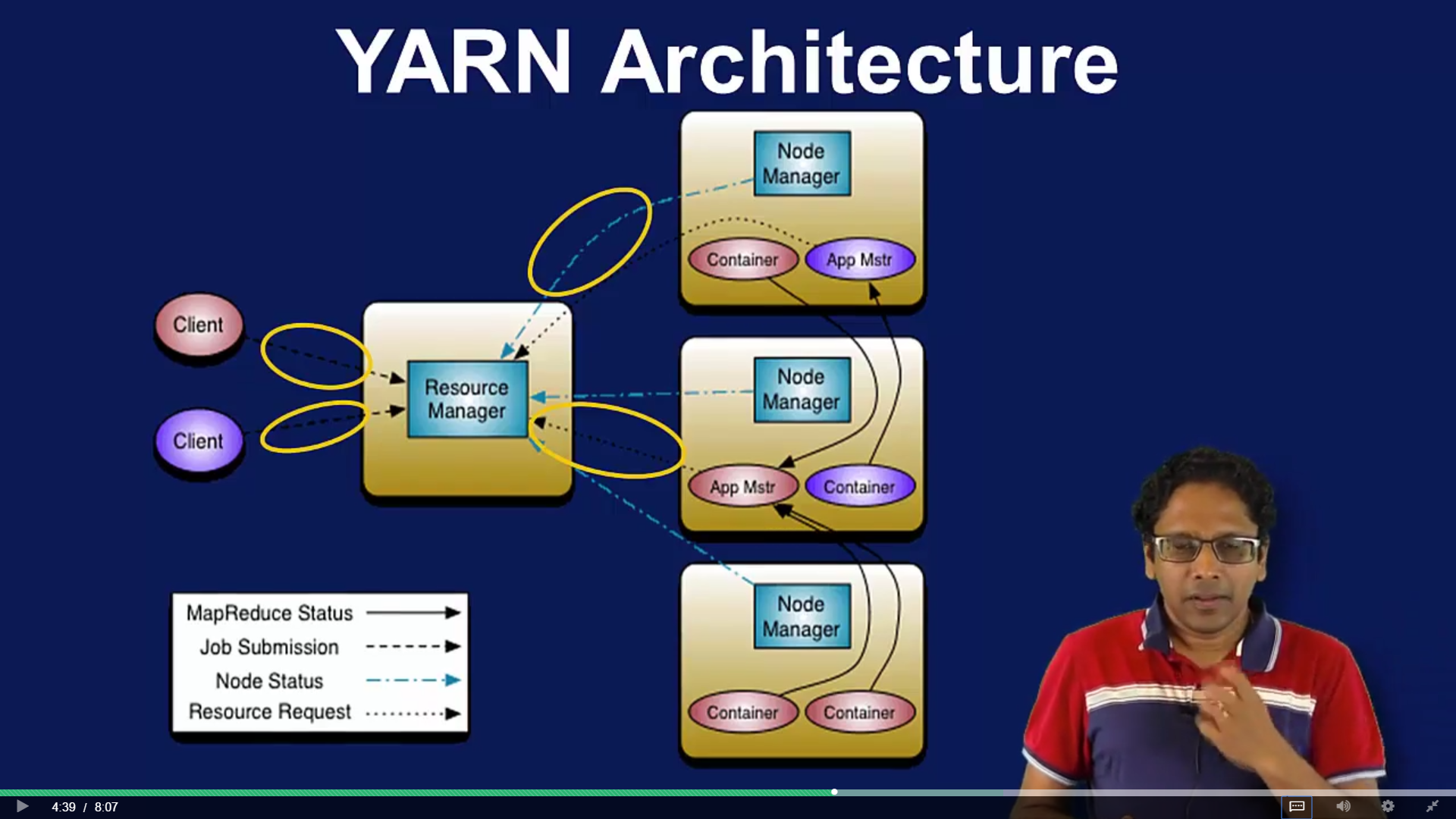
- Main Idea Separate Schuduling and resourse management job trcking
- Job tracking responsibility is spread out to mulitple application managers
- High availability resourse manager
- use Cgroup to mange resources used by containers
- YARN web services
- timeline server
Hadoop Execution Environment
Original model:
map reduce, works for good amount of thinsg but not all
for instance with iteration(like ML algorithms)
- tez, yarn, spark (DAG)
- memory caching
Tez:
- can handle DAG
- Dynamica DAG changes
- customize data format( not necessary key-val)
- Pig and Hive already use Tez
Spark:
- inmeory processing
- can handl cyclic
Hadoop Resourse Scheduling
- Motivations for scheduling ?
- important work may have to wait
- Policies
- FIFO (Defalt)
- Fair Share
- Capacity