Lesson 1: Big Data Hadoop Stack
Hadoop Basics
open sourced storage processing cluster of commodity of hardware
Why scalable why useful?
Batch processing framework
Move computation to data
Higher level abstraction: Pig Latin, Hive (SQL)
- Processes:
- Tasktracker + jobtracker
- Namenode + Datanode
Apache Framework: Basic Module
Hadoop Common: common libraries and stuff HDFS Hadoop MapReduce Yarn
HDFS
Distributed, scalable, and portable file system written in Java to support Hadoop Framework.
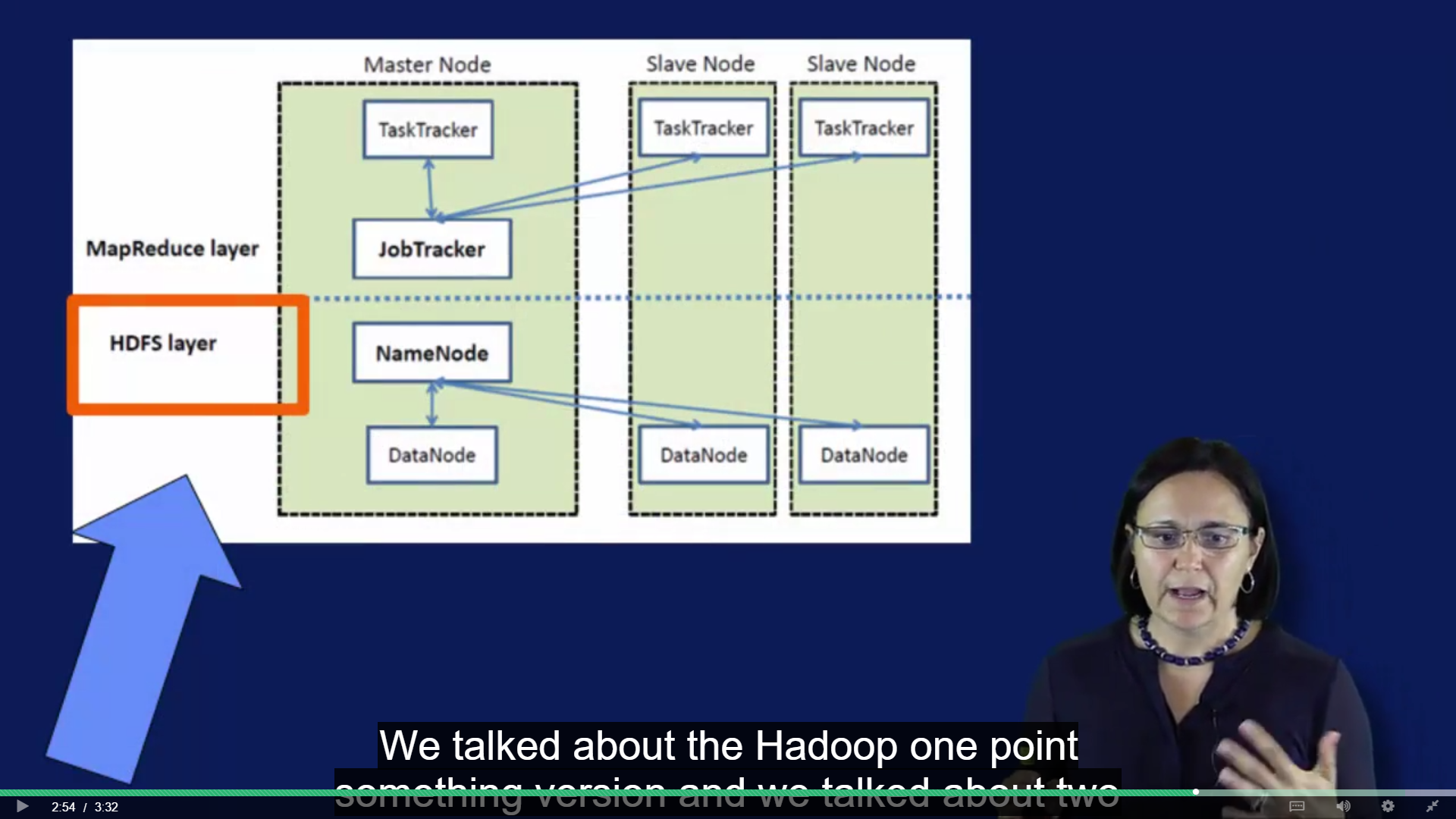
Notice the naming convention: upper lvl is for MR layer, lower lvl is for HDFS layer.

Namenode
typicall one single namenode but a cluster of data nodes
secondary namenode does NOT take over when primary namenode is down. It takes snapshots
Mapreduce Engine
jobtracker: client submit request to jobtracker jobtracker pushes work out to tasktracker --> with keeping balance as possible
YARN
MRV2: mapreduce version two
provides processing model that is beyond map-reduce processing model.
split up: jobtracker, resource management, job scheduling, job monitoring
into two
global resource manager and application resource manager
YARN focouses on scheduling, compatible with MapReduce
can now support additional engine like graph processing, iterative modeling etc.
now it is very good for ML
ZOO
Higher level hadoop stack
have data, want to access those data using SQL like language
zookeeper is playing the role like Chubby
SQOOP
SQL to Hadoop: can load entire table into HDFS
HBASE:
Key component, support data need fast / random access to the HDFS Based on Google BigTable, Key Value storage, not relational database
PIG
Scripting language describe data analysis problems as data flows can have pig in JRuby, JPython, Java
Pig for ETL, UDF(User Defined Function)
HIVE
Apache hive, data warehouse system SQL like language: Hive QL facilatates querying Compiles to MapReduce work
Oozie
Workflow schedule system DAGs, job scheduling
ZooKeeper
- Operational services : dist configuration services
- Centralized, synchronyzation,
Flume:
collection, aggregating, moving log data
Some Additional component
parallel database technology
Spark: in memory processing, multi-stage, good for complex analysis (very very good for machine learning)
Impala
works on HDFS directly ~ Hive(compiles to mapreduce)